
DeepSeek-V3 achieves a significant breakthrough in inference speed over previous models.
It tops the leaderboard among open-source models and rivals the most advanced closed-source models globally.
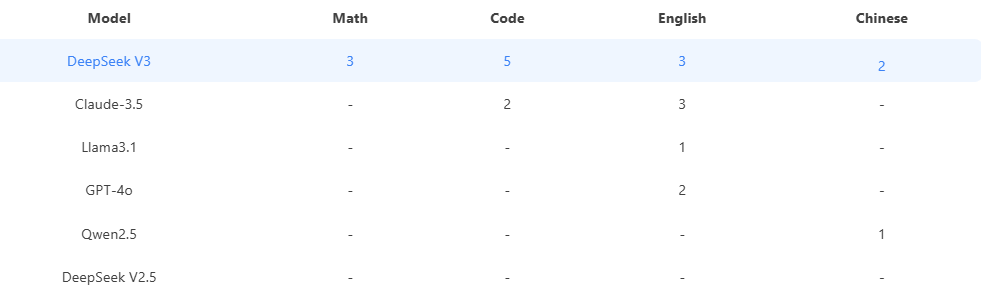
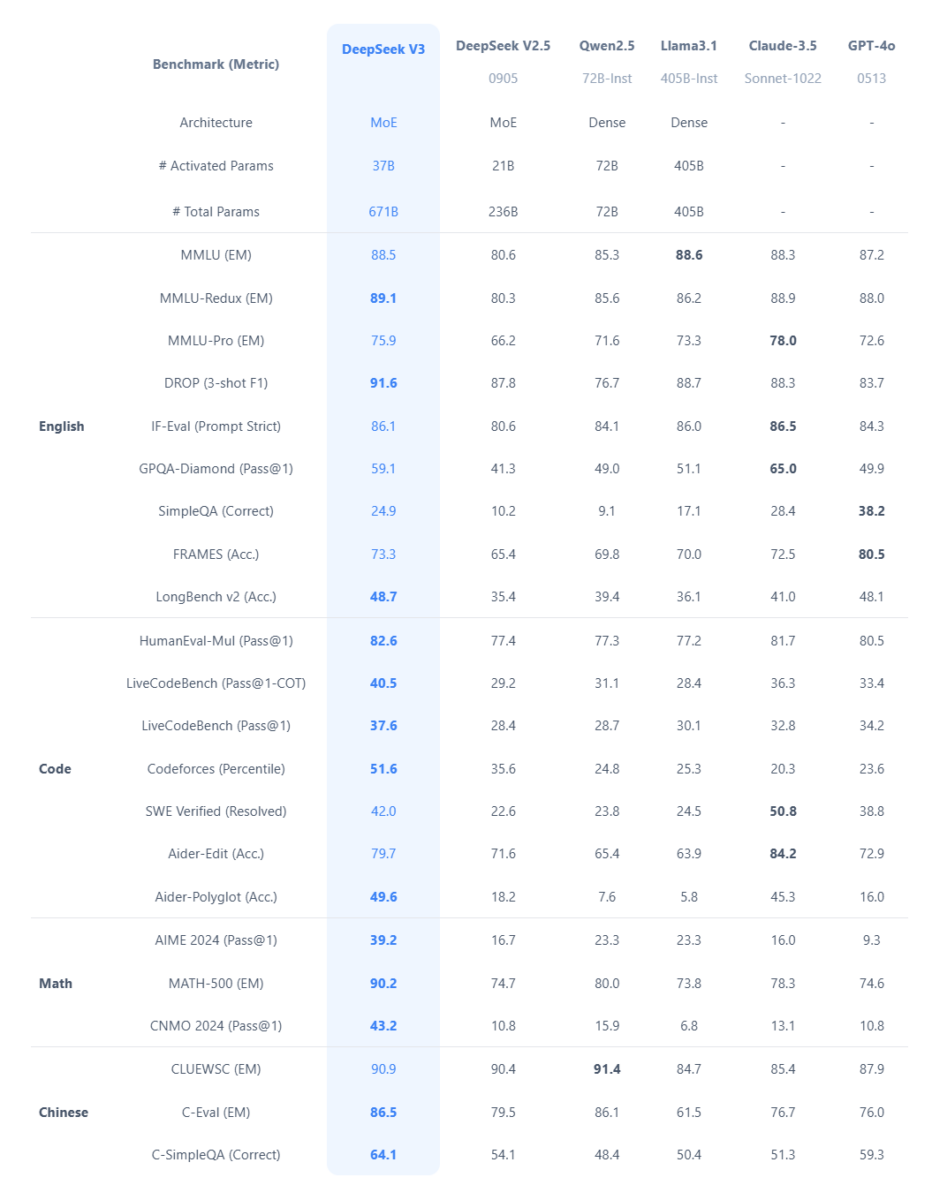
Models Benchmark
Recommendations
- Choose DeepSeek V3 for math, coding, or Chinese tasks.
- Use Claude-3.5 for complex reasoning (e.g., GPQA-Diamond) or software engineering.
- Opt for GPT-4o for tasks requiring factual accuracy (SimpleQA) or dialogue (FRAMES).
- Consider Qwen2.5 for Chinese-specific applications.
This comparison underscores the importance of task-specific model selection rather than relying on a single “best” model.



